Il existe plusieurs patterns d’architecture qui peuvent être intéressants en fonction des contextes. Chaque architecture apporte son lot de solutions et de problèmes et il n’y a pas d’architecture miracle qui fonctionnerait dans tous les contextes. Il est nécessaire de comprendre les gains et les coûts des architectures pour trouver une solution adaptée. Pour faire les bons choix il faut prendre du recul et parfois retarder les prises de décisions pour avoir le temps mieux comprendre et s’approprier les problèmes et les contraintes d’un projet. L’erreur étant toujours possible, il faut aussi rester en capacité de revenir sur certains choix techniques sans avoir à reprendre tout le code de l’application.
Les architectures en couches permettent d’obtenir ces bénéfices. Pour savoir comment tirer ces bénéfices il faut comprendre le principe de base des couches, voir comment ces principes se matérialisent et comment ils manifestent dans d’autres architectures en couches comme l’architecture hexagonale et la clean architecture.
Table of contents
Open Table of contents
Principe de base
En se basant sur le livre Pattern - Oriented Software Architecture, les couches sont un pattern qui a pour objectif de décomposer une application en regroupant le code par niveau d’abstraction. C’est un style d’architecture à utiliser dans le cadre d’application suffisamment large et complexe pour que le découpage en couches apporte de la clarté dans la structure de l’application.
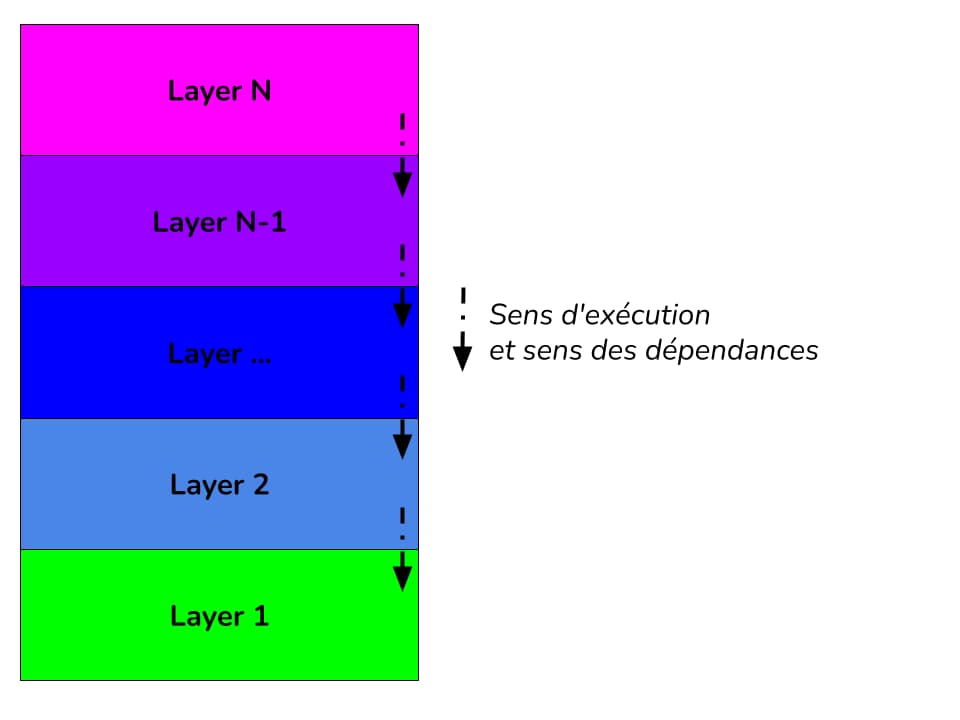
Les couches sont organisées généralement en fonction du niveau d’abstraction. Les couches hautes vont permettre à l’utilisateur d’interagir avec l’application et les couches basses permettent à l’application d’interagir avec le “matériel” (BDD, file system, cache, etc). Parmi les contepts au coeur de ce style d’architecture il y a le sens des dépendances et le sens d’ exécution. Une couche doit dépendre et uniquement appeler que les couches plus basses. Le sens d’exécution part des couches de haut niveau d’abstraction vers les couches avec des niveaux d’abstractions plus bas. Une couche propose un service à la couche supérieure en utilisant les éléments composant la couche inférieure et en servant d’interface avec un niveau d’abstraction plus haut.
Il est possible d’avoir deux variantes, la première que je vais appeler “classique” (ou “stricte”) qui limite les interactions d’une couche avec la couche directement inférieure. Une couche N ne peut interagir qu’avec la couche N-1. La seconde variante “souple (“Relaxed” dans le livre) qui autorise une couche à interagir avec toutes les couches inférieures sans forcément passer par toutes les couches intermédiaires. C’est un gain de flexibilité au détriment de la maintenabilité. Faire dépendre de couches avec des niveaux d’abstractions différentes d’une seule et même couche va augmenter le couplage avec cette couche.
C’est une approche qui peut avoir son utilité dans des contextes ou une couche ne fait qu’appeler directement la couche suivante (on parle de passe-plat). Dans ces contextes cette approche plus souple peut avoir des bénéfices en respectant d’autres principes, mais ça sera le sujet d’un autre article.
Toujours dans cet ouvrage, on trouve la description de l’adaptation de ce style d’architecture pour des applications.
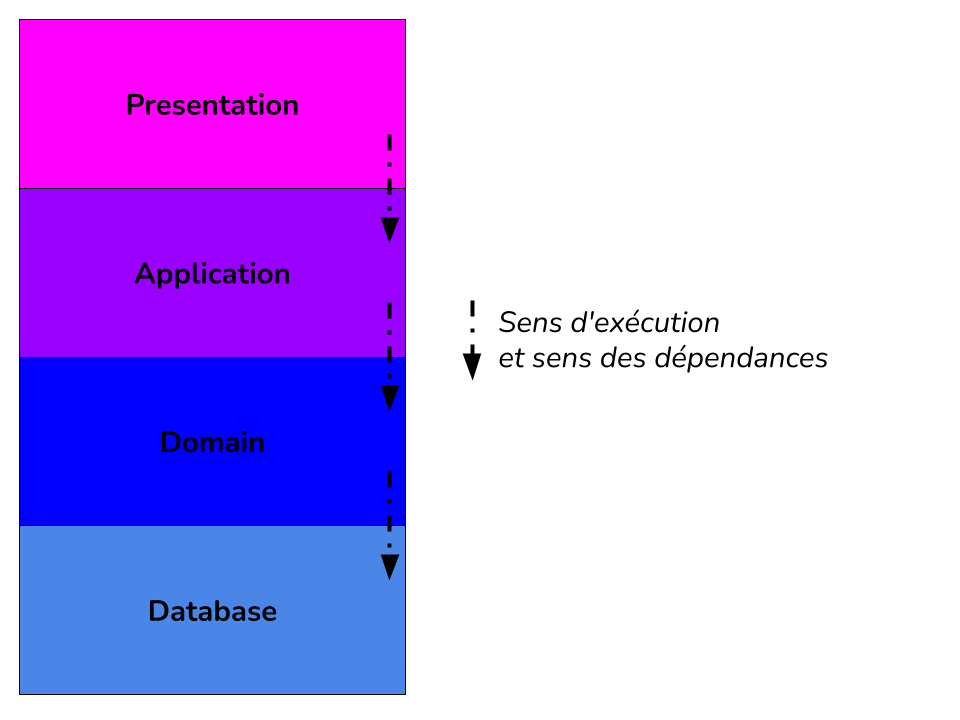
- Presentation Layer : Le code lié à l’interface utilisateur.
- Application Layer : Le code qui permet d’exposer l’application (les controlleurs par exemple).
- Domain Layer : La logique “métier” ou algorithmique de l’application.
- Database : La code permettant d’accéder à la BDD.
Cette adaptation avec 4 couches d’architecture permet de séparer les responsabilités et de limiter le couplage entre les
couches. Apporter un changement dans une couche implique seulement de changer les couches qui en dépendent. Les évolutions
de la couche Presentation n’impliquent pas de faire changer les autres couches puisqu’aucune couche ne dépend d’elle.
Les évolutions ne se propagent pas forcément dans toutes les couches en remontant. Faire évoluer la couche Domain
implique de faire évoluer la couche Application, mais pas forcément la couche Presentation. Une couche sert d’interface
entre sa couche précédente et sa couche suivante, ce qui limite l’impact des changements en remontant dans les couches.
La couche ‘Database’ est la plus basse cette adaptation ce qui signifie que les changements de la base de données ne sont pas le résultat d’évolutions d’autres couches, mais tous les changements dans cette couche vont impliquer des changements dans d’autres couches. Le design de cette couche va influencer le design des couches supérieures.
C’est sur cet aspect (mais pas uniquement) que les adaptations suivantes des architectures en couches apportent des changements.
Inversion de dépendances et sens d’exéctution.
Aujourd’hui quand on parle d’architecture en couche on parle souvent de clean architecture ou d’architecture hexagonale et on trouve aussi des adaptations plus ou moins libres de ces architectures. Bien que ces architectures suivent le principe des couches pour décomposer une application il y a quand même des différences notamment dans le sens des dépendances et l’organisation des couches.
La distinction majeure se fait sur l’isolation et l’indépendance de la couche avec la logique métier/algorithmique (Domain
sur le schéma précédent) des autres couches. On trouve parfois la formule “domain centric” pour parler de ce style
d’architecture. C’est cette logique qui devient le centre de l’architecture et de l’application, car c’est cette logique
qui est différenciante par rapport aux applications concurrentes. C’est cette couche qui donne sa valeur à l’application
et qui justifie la raison d’existence de l’application. L’objectif est de faire dépendre le reste de l’application de
cette logique. Ça ne rend pas les autres couches inutiles ou non importantes, mais elles vont exister pour supporter
l’apport de la valeur de la couche Domain.
C’est le principe d’inversion de dépendance (D de SOLID) qui permet de changer le sens des dépendances et de rendre central la logique “métier”.
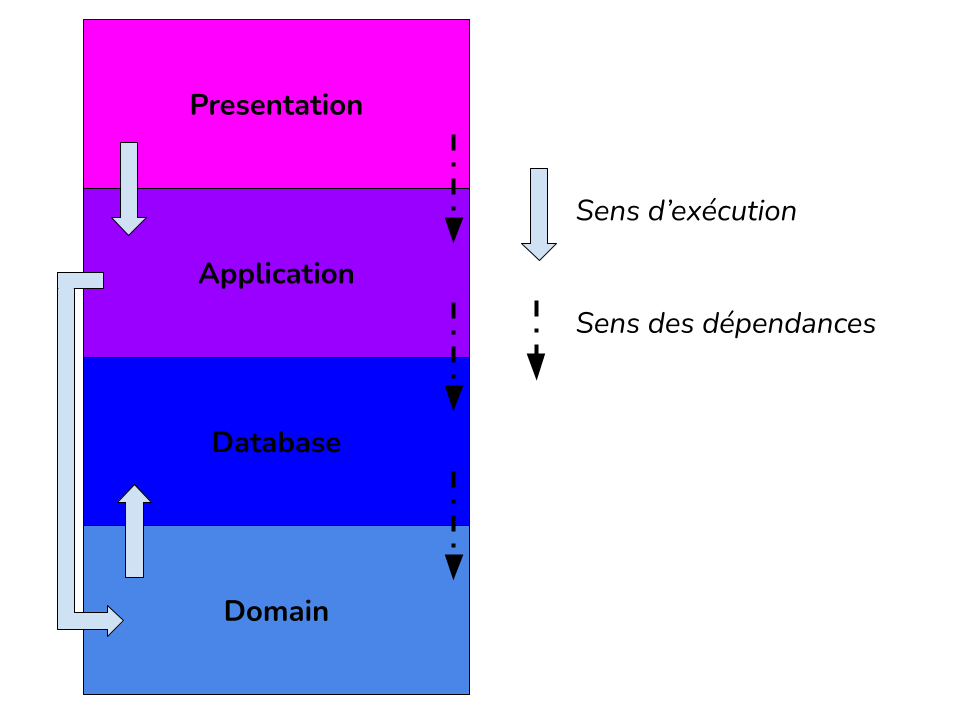
Il est important de comprendre que malgré le changement du sens des dépendances le sens d’exécution ne change pas.
On a généralement toujours le même sens d’exécution :
Application => Domain => Database
Controller => Service / Use Case / Port => Database
Le besoin de persister les changements après avoir appliqué la logique ne disparaissant pas, le sens d’exécution ne change pas. Cependant, changer le sens des dépendances n’impose pas de devoir changer le sens d’exécution.
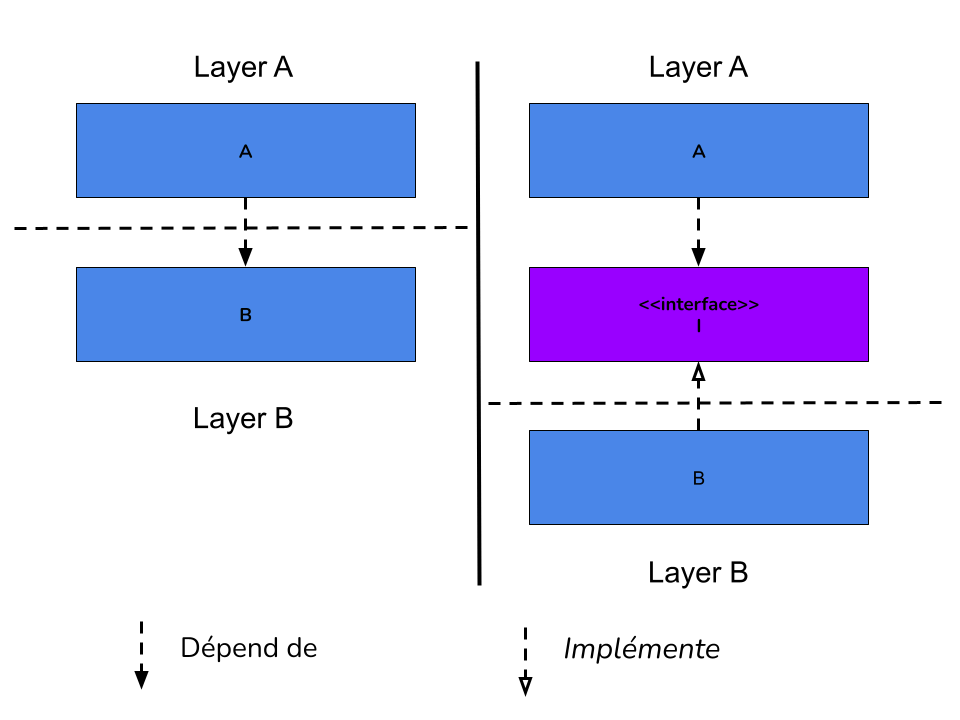
Pour inverser les dépendances il faut définir dans la couche Domain une abstraction (interface) dont la couche va
dépendre pour interagir avec la base de données. La couche Database va implémenter cette abstraction, mais c’est la
couche Domain qui a la responsabilité de l’abstraction qui ne doit changer que dans le cas où les besoins du Domain
change.
Certains langages avec un typage uniquement dynamique comme le JS ou le Ruby n’ont pas le concept d’interface ni de vérification de type, mais ce principe peut quand même s’appliquer. Il faut considérer que tout paramètre que l’on passe à une fonction ou une méthode est une abstraction. Le code dépend de ces abstractions qui ont des méthodes particulières.
Dans ces contextes on peut se passer des interfaces et les faire exister uniquement d’un point de vue conceptuel et sans
les matérialiser avec des fichiers. L’inconvénient c’est que cela demande une plus grande rigueur pendant le développement,
il est possible de faire évoluer les implémentations des abstractions en perdant de vu que c’est la couche Domain qui
doit définir la forme de l’abstraction. Il reste possible de créer des fausses interfaces dans ces langages en créant des
classes avec des méthodes qui lancent des exceptions et qui doivent être surchargées dans les implémentations.
C’est une tactique qui peut servir de garde-fou, mais ne remplacera pas une vérification de type.
Architecure Hexagonal
L’architecture hexagonale formalisée par Alistaire Cockburn a pour intention de permettre à une application d’être pilotée indépendamment par un utilisateur, un programme, un script ou des tests et de permettre de développer l’application en isolation de son environnement (BDD par exemple). C’est l’utilisation d’une adaptation du design pattern ‘Adapter’ qui permet d’obtenir ces propriétés dans cette architecture.
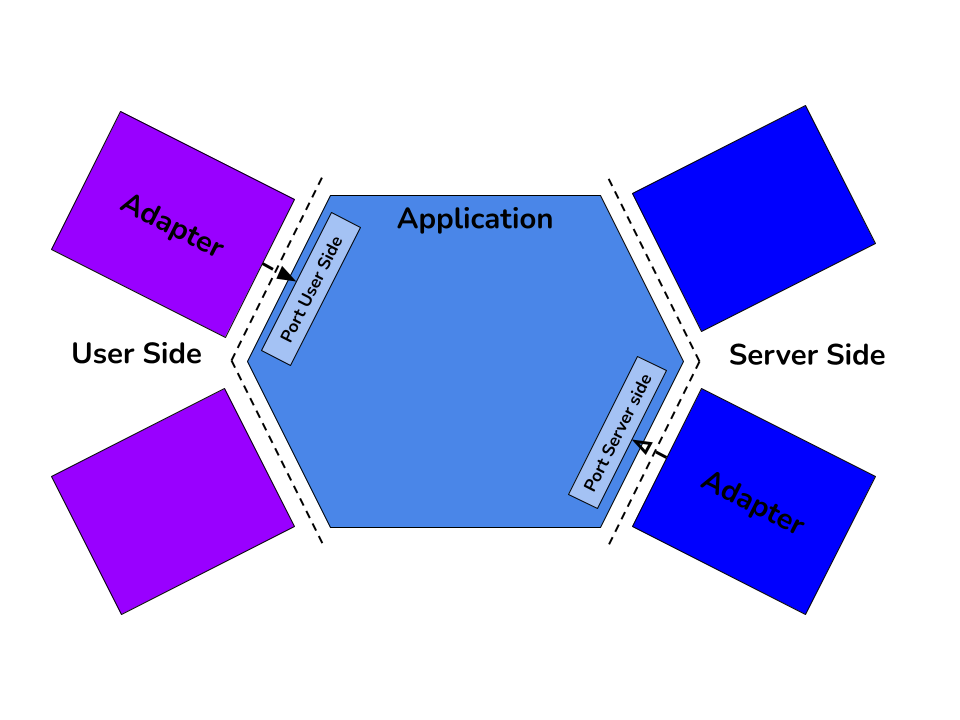
Cette architecture propose de décomposer l’application en 3 parties.
User Side : C’est le code qui permet de piloter l’application, on peut trouver les controllers, les scripts, etc.
Application (l’hexagone) : C’est la logique qui doit être pilotée.
Service Side: C’est le code piloté par l’hexagone, c’est ce dont dépend l’hexagone (BDD, File system, etc).
Les interactions pour entrer et pour sortir de l’hexagone sont faites en respectant le même principe en suivant le pattern
adapter. Pour piloter l’application (entrer dans l’hexagone - User Side) le code qui appelle un port défini par l’hexagone.
Pour fournir un service à l’application (sortir de l’hexagone - Server Side) l’hexagone fournit un port (une abstraction,
une interface) pour interagir avec l’extérieur.
Il y a une volonté d’uniformiser les interactions avec l’hexagone à travers l’utilisation des ports. L’hexagone définit comment on interagit avec lui et les éléments qui veulent interagir avec l’hexagone se conforme au “protocole” de communication défini par l’hexagone.
Pour illustrer ce principe la comparaison avec le réseau électrique d’une maison est souvent utilisée. Tous les appareils électriques ont besoin d’être branché pour fonctionner. Cependant, chaque appareil n’est pas construit avec sa propose prise électrique (on a toujours 2 pôles et parfois la terre), ce qui permet de se brancher sur les prises murales d’une maison. On a défini une manière de brancher au réseau électrique et tous les appareils électriques s’y conforment. Ce qui évite d’avoir à installer une nouvelle prise électrique à chaque achat d’un nouvel appareil.
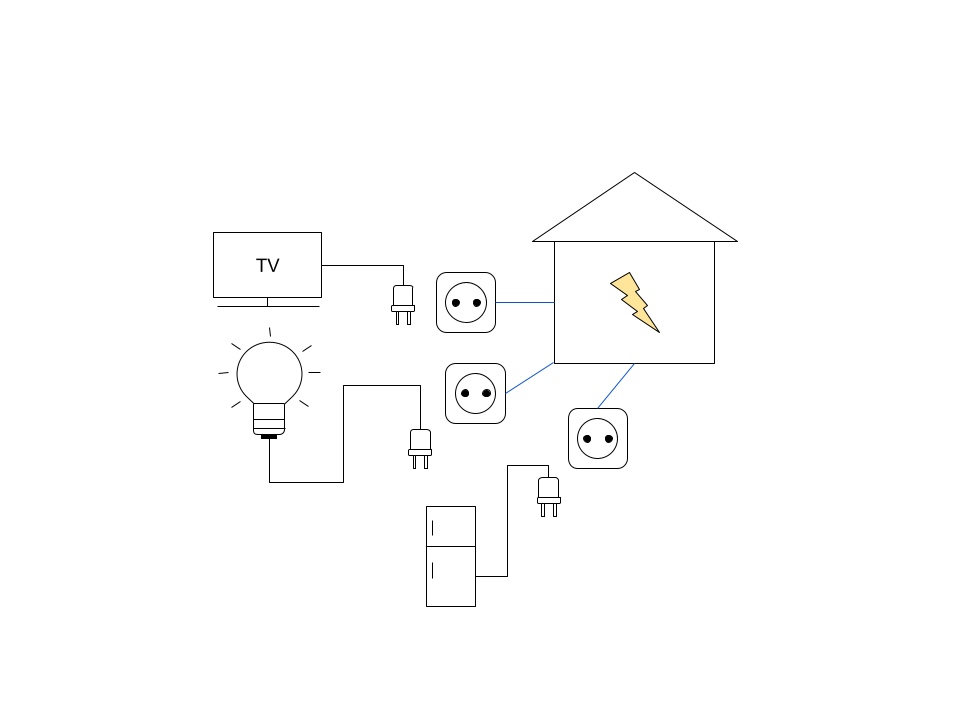
Port Server Side et Adatpers
L’application doit parfois interagir avec le matériel (BDD, système de fichiers) pour atteindre son but. Pour inverser les
dépendances c’est hexagone qui va définir l’interface dont il a besoin pour interagir. C’est l’implémentation de ce port
qui sera l’adapter dans la partie Server Side. C’est en définissant l’interface dans l’hexagone qu’on inverse le sens
des dépendances. Comme l’interface vient de l’hexagone le sens d’exécution peut rester le même sans casser les sens des
dépendances. Il peut y avoir plusieurs adapters avec la même interface, c’est quelque chose qu’on peut observer avec les
fausses implémentations dans les tests pour s’isoler d’une base de données.
Port User Side et Adatpers
Les ports User Side sont les points d’entrées vers la logique de l’application. On va considérer comme des adapters le
code qui appellent ces ports (scripts, controllers). Comme l’adapter appelle le port le sens d’exécution respecte le
sens des dépendances. Le sens des dépendances étant respecté l’utilisation d’une interface dans ce cas n’est pas indispensable.
L’utilisation d’une interface pour cette frontière de l’architecture va dépendre du contexte de ce que l’équipe cherche à
obtenir.
Pour plonger plus concrètement dans le fonctionnement de cette architecture et voir des exemples d’implémentation je vous suggère de regarder l’article Hexagonal architecture d’Alister Cock et l’article Architecture Hexagonale : trois principes et un exemple d’implémentation de Sébastien Roccaserra.
Clean Architecture
La clean architecture spécifiée par Robert Martin tente d’intégrer plusieurs propriétés qui viennent de différentes sources (Architecture Hexagonal, Onion Architecture, DCI, BCE, Screaming Architecture).
L’intention est de produire des systèmes qui vont respecter ces 5 propriétés :
- Indépendance avec le framework.
- Indépendance avec l’UI.
- Indépendance avec la base de données.
- Indépendance avec les systèmes externes.
- Testable.
Le système ne doit pas fortement dépendre de l’existence ou de l’utilisation d’un framework, de l’ interface utilisateur, de la base de données ou de systèmes externes. C’est la logique métier qui doit être le coeur du système.
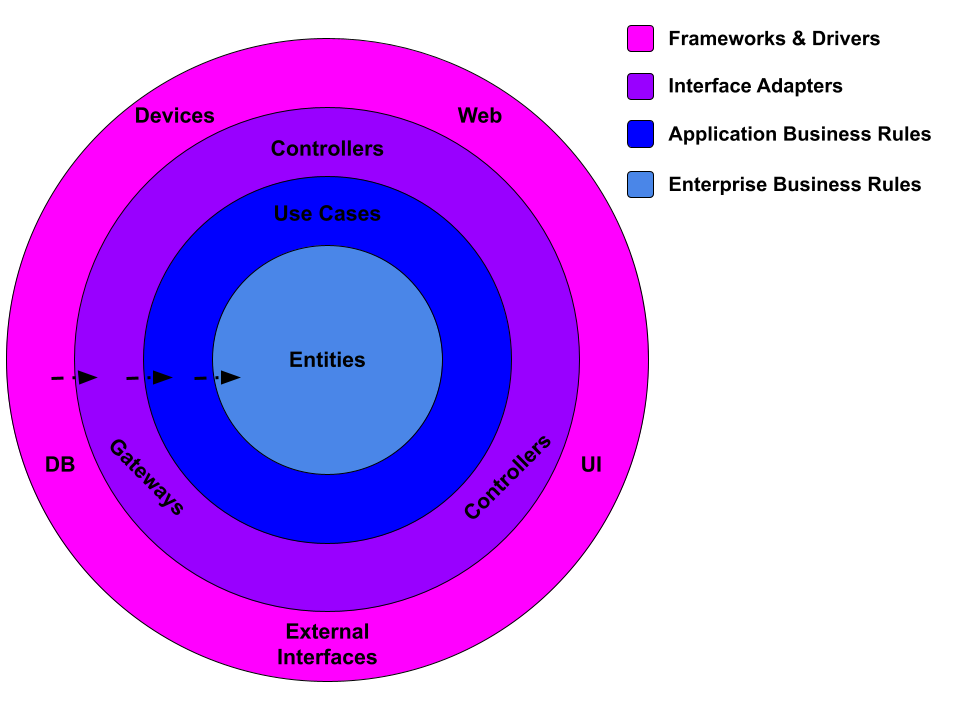
- Frameworks & Adapter : Dans cette couche il y a le code lié au framework, le code lié à la base de données, en soit tout le code permettant d’interagir avec l’extérieur du système.
- Interface Adapters : Dans cette couche on trouve des
adaptersqui vont transformer les données du format des use-cases et desentitiesdans des formats pratiques pour la coucheFramework & Adapters. - Application Business Rules : Dans cette couche on trouve les use-cases qu’on peut associer aux fonctionnalités de l’application.
- Enterprise Business Rules : Cette couche contient la logique métier.
Cette architecture donne plus d’indications sur comment organiser et nommer les choses par rapport à l’architecture Hexagonal.
Il y a une distinction plus forte sur comment faire les choses et comment les nommer. Par exemple pour le code permettant
d’accéder à la base de données on va parler de Gateway, pour le code traitant les requêtes, on parle de controllers.
Chaque responsabilité est nommée et différenciée. L’organisation des couches est aussi différente il y a une distinction
forte entre intérieur et extérieur de l’application et la notion “piloter” et “être piloté” est moins présente. Par exemple,
on trouve les controllers (qui pilotent la logique métier) dans la même couche que les Gateways(qui sont pilotées par
la logique métier). On voit aussi apparaître 2 couches Enterprise Business Rules et Application Business Rules qui
contrairement à l’architecture hexagonale indique modestement comment organiser et composer la logique métier”.
Use Case
Ce sont les points d’entrées de la logique métier, ils font la liaison entre la logique métier qui est dans la couche
Enterprise Business Rules et les besoins / contraintes techniques (persister des données par exemple) porter par la couche
Interface Adapters.
These use cases orchestrate the flow of data to and from the entities, and direct those entities to use their enterprise wide business rules to achieve the goals of the use case.
Robert C. Martin
Les use-case ne sont pas censés contenir trop de logique, ils doivent se reposer sur la couche Enterprise Business Rules
et les entities pour composer le comportement attendu. Les use-case ayant déjà une responsabilité (faire la liaison
entre la logique et les besoins techniques) ajouter de la logique à l’intérieur augmente leurs responsabilités et les rend
plus d1ifficile à comprendre et maintenir.
Un des effets de cette pratique que j’ai pu observer en mission est qu’en cas d’évolution impliquant de récupérer des
données supplémentaires si les use-cases contiennent déjà de la logique ils deviennent l’endroit le plus évident pour
ajouter la logique. Dans ce cas nous avons souvent la tentation de simplement rajouter une dépendance au use-case pour
retrouver les données manquantes. Cette approche finit par faire dépendre les use-cases de nombreuses abstractions
permettant d’accéder à la base de données. Plus le use-cases a de dépendances vers la base de données plus les chances
que les dépendances représentent l’organisation des données en base sont importantes. En arrivant à ce stade on perd une
partie de l’isolation entre la logique métier et de la base de données et en cas d’évolution de schéma de base de données
on doit venir changer les dépendances du use-case et sa logique. On fait l’effort de mettre en place une architecture
isolant BDD et logique métier sans pouvoir en tirer les bénéfices.
Il existe un schéma montrant comment créer l’isolation entre la couche Application Business Rules (les use-cases) et
la couche Interface Adapters (Controllers et Presenters).
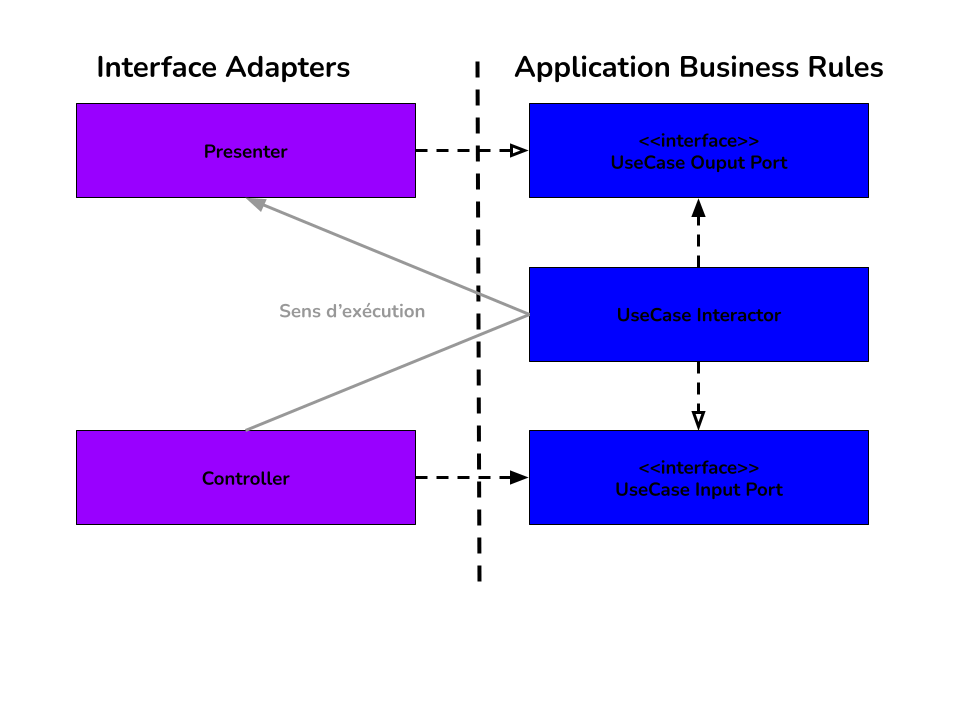
Le Controller va dépendre d’une interface UseCase Input Port qui sera implémentée par le UseCase Interactor.
UseCase Interactor dépend d’une interface UseCase Output Port avec une méthode pour passer des données au Presenter
(présente généralement) qui sera appelée par le UseCase Interactor pour passer des données au Presenter (pas de valeur
de retour direct depuis le use-case, mais un effet de bord sur le Presenter).
J’ai rarement rencontré de gens ayant mis en place de la clean architecture sur leur projet en ayant respecté ce schéma assurant un bon niveau d’isolation, mais apportant son niveau de complexité. Je vous laisse seul juge de son utilité dans vos contextes respectifs.
Entities
Les “entities” sont les éléments qui vont contenir la logique et il est possible d’avoir des objets, mais aussi des structures
de données et des fonctions donc pas de limitation à la programmation orientée objet. Cependant, attention la programmation
fonctionnelle ce n’est pas uniquement des fonctions et des structures de données, il faut aussi embarquer les principes
et les mécaniques ce paradigme de programmation si c’est l’approche que vous choisissez pour vos entities.
L’idée est de pouvoir réutiliser les entities dans les différents use-cases. Les changements ayant lieu dans les autres
couches de l’application ne doivent pas impliquer des changements dans les entities.
Pour creuser un peu plus le sujet je vous invite à consulter l’article The Clean Architecture de Robert Martin, mais aussi à regarder le talk The Clean Architecture de Ian Cooper et le talk Adoptez la clean archigonale de Christophe Breget-Girardin.
Une adaption libre avec 3 couches
Lors de discussions avec des collègues et sur certaines missions j’ai constaté qu’on peut trouver souvent des adaptations prenant des éléments dans l’architecture hexagonale et la clean architecture et en retirant des éléments trop contraignants. On peut représenter ces adaptations avec schéma suivant.
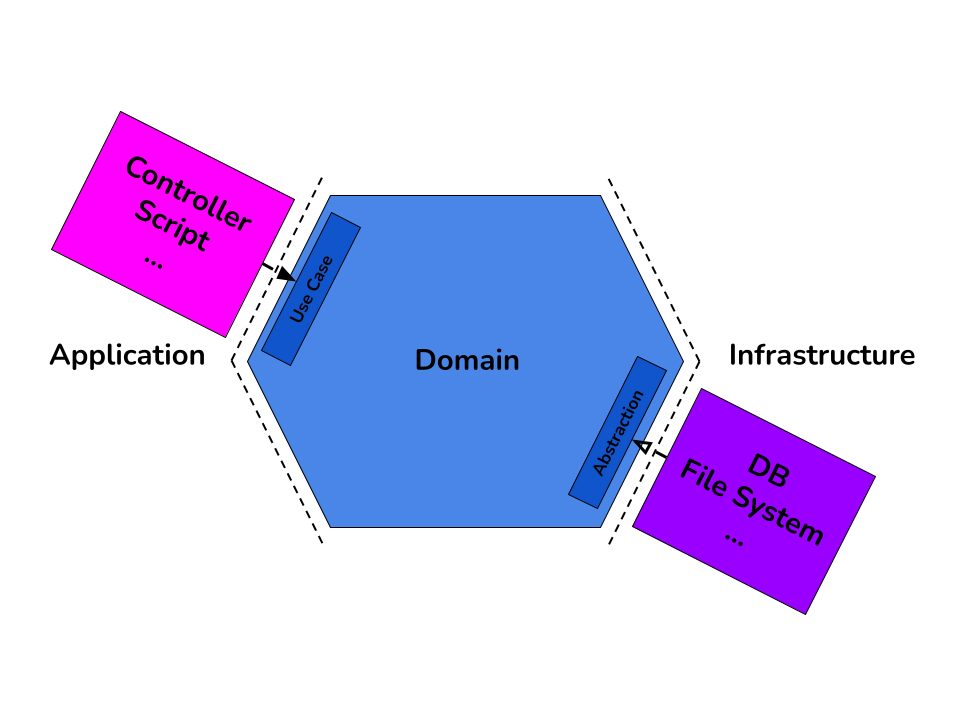
On y trouve 3 couches : Application, Domain, Infrastructure
On peut trouver l’origine du nom de ces couches à travers cet article Application / Domain / Infrastructure : des mots de la Layered Hexagonal Clean Architecture ? de Sebastien Roccaserra.
Application
Dans cette couche on trouve le code qui permet d’exposer l’application à l’extérieur (framework, contrôleur, script, cron)
Ce qui se rapproche des adapters de la partie User Side de l’architecture hexagonale.
Domain
On trouve la logique métier dans cette couche. On y trouve généralement une version simplifiée des use-cases
sans l’utilisation de UseCase Interactor, UseCase Input Port et UseCase Ouput Port. Avec les use-case cohabitent
objets, structure de données, service et tout élément permettant d’avoir de la logique. Et enfin les abstractions (quand
elles existent) des dépendances utilisées par le domaine. Il peut y avoir plusieurs pattern utilisés, mais un des plus
représentés est le pattern [repository] (https://martinfowler.com/eaaCatalog/repository.html).
C’est un fusion des couches Application Business Rules et Enterprise Business Rules de la clean architecture.
Infrastructure
Enfin dans cette couche on trouve tout le code qui permet d’accéder à l’extérieur de l’application depuis la couche Domain
donc les implémentations pour les interfaces dont dépend le domaine et tout le code utilisant l’infrastructure (BDD,
Système de fichier, logger, service http, etc).C’est une couche plutôt proche des adaptersde la partie Server Side de
l’architecture hexagonale.
On retrouve un découpage proche de celui proposé de l’architecture hexagonal (Ce qui pilote l’application / ce qui est piloté par l’application) mélanger avec le concept de use cases.
Combien de couches ?
Le nombre de couches peut varier, il faut malgré tout garder deux choses en tête.
Trop de couches peut rendre l’application complexe à comprendre à cause des différents niveaux d’indirection. Trop peu de couches peut aussi être problématique, car trop de responsabilités au même endroit rend le code difficile à comprendre et donc à maintenir. C’est un problème qui peut réduire notre capacité à réutiliser ces couches.
Il est possible d’utiliser les tests pour savoir si une couche est nécessaire ou pas. Si tester le code n’est pas évident, on peut envisager de rajouter une couche. Ensuite, il faut savoir si le sens des dépendances est acceptable et si nécessaire inverser les dépendances. Il est aussi possible de découper le code sans faire apparaître de couche, par exemple si le code d’une classe peut être répartie dans deux classes si le tout reste cohérent.
Il faut garder en tête le sens des dépendances en rajoutant une couche, les relations de dépendances doivent toujours se diriger vers la logique métier.
Conclusion
Les architectures en couches sont plutôt flexibles et peuvent être adaptées en fonction des contextes, bien que ça ne fasse pas d’elles des solutions miracle. Peu importe le style d’architecture, il y a souvent des gains à faire une décomposition technique de l’application et c’est sur ce point que les principes et mécaniques des architectures en couches sont intéressants car ils restent assez basiques et facilement implémentables. Il est aussi possible de piocher des éléments intéressants dans ces architectures et de les adapter tant qu’on a conscience de ce que l’on gagne et ce que l’on perd à faire ces adaptations.
Référence
- Pattern - Oriented Software Architecture - Frank Buschmann, Regine Meunier, Hans Rohnert, Peter Sommerlad, Michael Stal
- Hexagonal architecture - Alister Cockburn
- Architecture Hexagonale : trois principes et un exemple d’implémentation - Sébastien Roccaserra.
- The Clean Architecture hexagone- Robert Martin
- The Clean Architecture - Ian Cooper
- Adoptez la clean archigonale - Christophe Breget-Girardin.
- D’une architecture web MVC à une architecture Clean Hexagonale - Céline Gilet
- Design Pattern Adapter
- Repository - Martin Fowler